目录
搭建一个零成本、永不失联的大模型 API 网关(附完整代码)
你是否曾为调用大模型 API 时的高昂费用而心疼?是否因为网上找来的免费 Key 经常失效、频繁手动切换而烦恼?如果有一个工具,能自动抓取免费的 API Key,并在背后悄无声息地帮你调度、切换,让聊天机器人永远不中断,而且完全免费,你想不想要?
今天我们就来手把手搭建一个开源、轻量、智能的 LLM API 代理网关。它像一个贴心的管家,帮你收集所有可用的免费 Key,按优先级使用,并在 Key 失效时瞬间切换到下一个,对你的聊天机器人(AstrBot、OpenClaw 等)完全透明。
痛点与解决思路
我们面临的困境
- API 调用太贵:个人开发者和小团队很难承担每月高昂的 Token 费用。
- 免费 Key 寿命短:社区分享、中转站赠送的 Key 通常几分钟到几小时就会失效或限流。
- 手动更换太麻烦:机器人正在运行,突然报错,你得登录服务器,手动更换配置中的 Key,服务就中断了。
这套方案如何应对?
这个项目是一个多层防御的智能网关:
- P0 层(最高优先):薅羊毛专用。爬虫定时从社区中转站抓取大量临时免费 Key,先用这些“快消品”,不用白不用。
- P1 层(稳定后备):官方免费资源。你自己申请的 Google Gemini、硅基流动、Groq 等每日有免费额度的官方 Key。当所有 P0 都挂了,系统无缝降级到这里。
- P2 层(最终保障):付费兜底。你自己的 OpenAI 或 DeepSeek 付费 Key,平时一分钱不花,仅在极端情况(所有免费渠道全断)下救急。
核心理念:优先烧完不稳定但免费的羊毛,官方稳定免费资源作为第二梯队,自己的付费 Key 当作保险丝。系统会自动在它们之间切换,而你只需在聊天框里正常说话。
技术架构一览
项目采用 Python + Flask + Waitress,单文件设计,极简部署。所有 Key 存储在内存中,无磁盘 I/O 延迟,响应飞快。
┌──────────────────────────────────────────────┐ │ proxy.py (单文件) │ │ │ │ ┌──────────┐ ┌─────────────────────┐ │ │ │ 爬虫线程 │─────▶│ 内存 KeyPool │ │ │ │(定时抓取) │ │ P0: 中转 / P1: 免费 │ │ │ └──────────┘ │ P2: 付费 │ │ │ └─────────────────────┘ │ │ │ │ │ ┌────▼────┐ │ │ │ 热备用调度器 │ │ │ └────┬────┘ │ │ │ │ │ ┌────▼────┐ │ │ │ 格式适配 & 请求转发 │ │ │ └────┬────┘ │ │ │ │ │ ┌────▼────┐ │ │ │Flask+Waitress│ │ │ │ 对外开放 API │ │ │ └─────────┘ │ └──────────────────────────────────────────────┘
核心模块:
- 爬虫线程:每 5 分钟抓取指定的 Key 数据源,并合并到内存池。
- 热备用调度器:维护一个
active_key和backup_key,当主 Key 失效时零延迟切换。 - 格式适配:自动识别 OpenAI 格式和 Google Gemini 原生格式,无需额外转换服务。
- Web 管理面板:增删供应商、数据源,查看日志和系统状态,全部在浏览器完成。
杀手级特性详解
1. 多源动态数据源,告别“写完即弃”
在 Web 面板上可以随时添加新的免费 Key 来源(URL),爬虫会自动遍历所有源抓取 Key。你不再需要修改代码,今天发现一个好用的中转站,粘贴 URL 就能立刻开始薅羊毛。数据源支持两种格式:
- 标准 groups 格式:
{"groups": [{"keys": [{"api_key": "...", "model": "..."}]}]} - 简化数组格式:
[{"key": "...", "models": ["..."], "provider": "..."}]
社区中转站普遍采用这种格式,非常适合批量抓取。
2. 多供应商支持:不止于中转,更拥抱免费生态
网关已经不再局限于社区中转 Key,而是将更多稳定、有官方免费额度的供应商纳入体系。
- NVIDIA NIM:每天免费调用 40 次/分钟,无需绑定信用卡。Endpoint 填
https://integrate.api.nvidia.com/v1,模型名使用nvidia/nemotron-3-super-120b-a12b等。 - GitHub Models:拥有众多模型,适合代码开发。Endpoint 填
https://models.github.ai/inference,模型名使用openai/gpt-4o-mini等。 - Cloudflare Workers AI:每日 10,000 个 Neurons 免费额度。Endpoint 填
https://api.cloudflare.com/client/v4/accounts/{account_id}/ai/v1,模型名使用@cf/meta/llama-3.1-8b-instruct等。 - Google Gemini:适用对话和内容生成。Endpoint 填
https://generativelanguage.googleapis.com/v1beta,模型名使用gemini-2.5-flash等。 - 魔搭社区 (ModelScope):国内直连体验好,每日 2000 次 免费调用。Endpoint 填
https://api-inference.modelscope.cn/v1,模型名使用deepseek-ai/DeepSeek-V4-Pro等。 - Cerebras & OpenRouter:支持通过 /models 接口探测和 OpenAI 兼容调用。
通过将这些官方免费额度资源加入 P1 层,网关实现了更高的稳定性和可用性,确保在社区 Key 失效时,仍有充裕的免费资源可供调度。
3. 智能调度:热备用+粘性+优先级
网关在设计上力求对上游友好,避免因频繁轮询导致 API 被限流:
- 优先级调度:严格按 P0(社区中转)> P1(官方免费)> P2(付费兜底) 的顺序使用 Key。
- 粘度保护:P0 Key 失败后先冷却 60 秒,连续失败 3 次才删除;P1/P2 Key 失败仅冷却不删除。
- 热备用切换:维护一个备用 Key,当当前 Key 失效时无缝切换。
model: "auto"智能路由:根据提示词内容(语言、是否包含代码等)自动选择最合适的模型。
通过引入冷却(Cooldown)与成功重置(Success Reset)的机制,网关避免了因一次临时错误就删除 Key 的情况,极大地保护了有限且宝贵的免费资源。
4. 自动无感切换
当请求中 model 为 "auto" 时,网关按优先级循环尝试所有可用 Key,直到成功或全部失败。每次尝试使用该 Key 的第一个支持模型(verified_models[0] 或 selected_models[0])。切换过程对前端完全透明,只返回最终成功响应或全部失败错误。
5. 极简请求处理:完全透传
网关的设计原则是尽可能不修改请求体,而是原样透传给上游。为了兼容不支持多模态的社区 Key,网关会自动移除 messages 中的 image_url 字段,只保留文本内容,避免上游 400 错误。同时,网关会根据供应商类型(OpenAI 兼容或 Google Gemini)自动构建请求 URL 和认证头。
6. 社区 Key 采集与粘度管理
爬虫线程从 sources.json 配置的数据源抓取社区 Key,每 5 分钟更新一次。社区 Key 失败时先冷却 60 秒,连续失败 3 次才删除。成功请求重置失败计数,实现“粘度延续”。爬虫更新时,保留现有社区 Key 的冷却时间和失败计数,避免因短暂故障而被误删。
7. Web 端可视化模型管理
告别修改配置文件的繁琐操作!在 Web 管理面板的供应商编辑页面,现在可以:
- 直接添加/删除模型:通过输入框手动添加模型,支持任意文本(如
openai/gpt-4o-mini、@cf/meta/llama-3-8b-instruct)。 - 一键探测模型:点击“探测可用模型”按钮,后端自动调用上游 API,返回该供应商支持的模型列表。
- 智能过滤:根据供应商类型自动过滤无效模型(例如 NVIDIA 只显示
nvidia/开头的模型)。 - 多选追加:探测到的模型会弹出模态框供用户勾选,点击“添加选中模型”即可追加到当前列表,不会覆盖已有模型。
- 实时保存:所有修改即时保存到
providers.json,无需重启网关。
8. 供应商手动测试
每个稳定供应商都配有“测试”按钮,点击后网关会发送一条简单的测试消息(例如“Say 'OK' if you are working.”)到上游 API,并显示状态码、延迟和响应内容。测试成功后,网关会自动更新该供应商的平均延迟(指数加权移动平均),并在表格中刷新显示。测试失败不会删除或冷却 Key,仅展示错误信息。
9. 零依赖部署与异步上报
- 单文件设计:整个项目仅依赖
proxy.py和templates/admin.html,无需复杂配置。 - 内置 Web 服务器:使用
waitress作为 WSGI 服务器,支持多线程并发。 - 异步更新机制:爬虫更新 Key 池、供应商探测、测试等操作均采用异步线程,不影响主请求处理。
- 日志与监控:所有请求日志写入
proxy.log,管理面板提供分页日志查看和健康状态卡片。
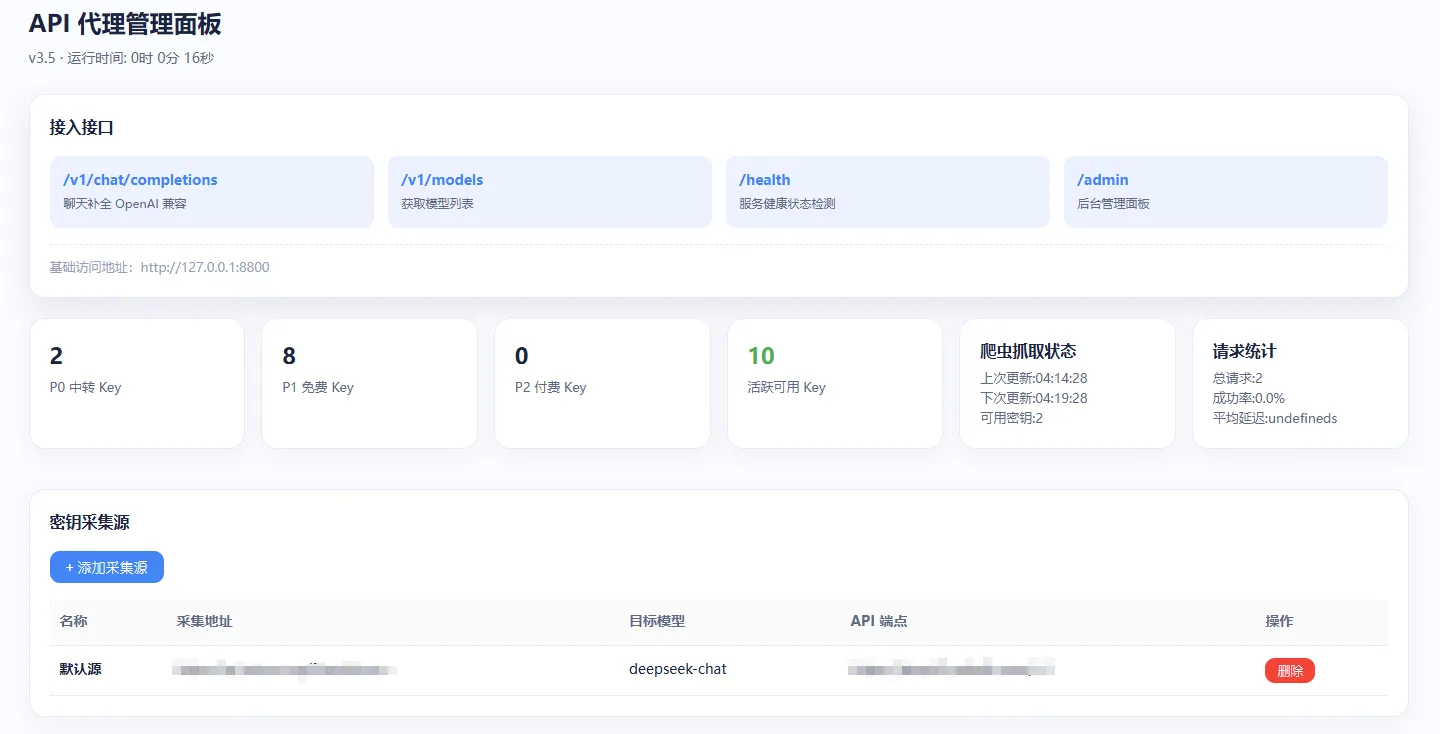
Web 管理面板
访问 http://127.0.0.1:8800/admin(默认账号密码 admin/admin),你可以:
- 添加/编辑供应商:配置名称、Endpoint、API Key、优先级、供应商类型,并手动管理模型列表。
- 探测模型:点击按钮自动获取上游支持的模型列表,勾选后追加到当前模型池。
- 测试供应商:一键测试连通性,显示状态码、延迟和响应预览。
- 管理数据源:添加/删除社区 Key 采集源(URL),支持自定义目标模型和 API 端点。
- 查看实时日志:分页浏览最近 200 条日志,支持自动刷新(3 秒间隔)。
- 系统健康监控:查看 Key 池统计(P0/P1/P2 数量、活跃 Key 数)、运行时间、爬虫状态、请求成功率等。
部署指南
- 下载代码:将
proxy.py和templates/admin.html保存到同一目录。 - 安装依赖:
pip install flask waitress requests cryptography - 运行:
python proxy.py - 配置数据源:编辑
sources.json,添加社区 Key 采集 URL(默认已配置一个测试源)。 - 添加稳定供应商:通过管理面板添加 P1/P2 供应商(如 NVIDIA、Cloudflare、Google 等)。
- 配置客户端:将你的聊天机器人(如 AstrBot、OpenClaw)的 API 地址改为
http://你的服务器IP:8800/v1,API Key 任意填写。
完整代码
- 后端
proxy.py:支持多供应商、多源数据抓取、热备用切换、自动清理多模态内容。 - 前端
admin.html:模型标签管理、探测模型模态框、日志自动刷新、供应商测试。
总结
这个网关的设计和实现凝聚了我们许多思考和实践。
- 它不是一个简单的代理,而是一个智能的“资源调度中心”。它通过多层防御和自动切换,将不同来源、不同稳定性的 API Key 融合成一个统一、可靠的接口。
- 它的核心优势在于“降本”和“增效”。P0层帮你最大限度利用免费羊毛,降低调用成本;P1层的官方免费资源和粘度管理保证了服务的稳定;而透明的Web管理面板和故障排查设计,则显著提升了开发和维护效率。
- 它的价值在于“免费”与“稳定”的平衡。通过精心设计的冷却与调度机制,我们能在享受免费资源的同时,确保服务的连续性和可靠性。这套方案不仅解决了当下的成本问题,更为未来接入更多优质、免费的AI服务奠定了基础。
对于个人开发者来说,这是一个极具性价比的解决方案。它让我们可以用极低的成本,体验到各种前沿的大模型能力。
希望这个项目的实现思路和最终成果能对你有所帮助。完整的代码和更详尽的技术细节,可以在下面的链接中找到。如果你有任何疑问或想法,也欢迎随时交流。
项目文档与代码仓库地址: https://github.com/yhyh0000/LLM-Proxy-Gateway
本文作者:苏皓明
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!